A plain comparison of enterprise survey software in 2026 — Qualtrics, Alchemer, SurveyMonkey and the rest — and the two questions that actually decide which one you need.
Enterprise survey software lets a big organisation run surveys across a lot of teams and a lot of years, with the security, permissions and reporting that size needs. The main ones in 2026 are Qualtrics, Alchemer, SurveyMonkey Enterprise, QuestionPro and Typeform for Business. They are all fine at asking questions. They differ in what happens to the answers afterwards — and that part has changed a lot in two years.
What changed
Reading text got cheap. Going through a thousand open-ended answers, or pulling three facts out of two hundred case notes, used to mean paying someone. It now takes minutes.
So teams stopped sending it out. It is hard to justify waiting a quarter for a consultant when your own staff can have the answer this afternoon.
Survey tools still mostly sell collecting. That was solved years ago. The AI most of them added reads what people type into a survey. It does not read the documents you keep.
The questions became longitudinal. Funders and boards want to know what changed for particular people, and why — which means finding the same person again next year, and reading what they wrote.
One person makes the reports. Everyone else waits.
Most places running surveys at any size have the same setup. One person turns responses into answers. Three or four others need those answers — for a funder, a board, a regional team, a programme review.
So the requests pile up. The regional director wants her region. Finance wants cost per outcome. A funder wants proof of one specific claim by Friday. It all lands on the same desk, and the honest reply is usually “next week.”
The usual fix is a dashboard. It takes months to build, and when it arrives it answers the questions someone thought of at the start. The first new question is never on it, so people queue up again behind whoever can write a query.
That is the real problem here. Not collecting the data. Getting from a question to an answer you can stand behind.
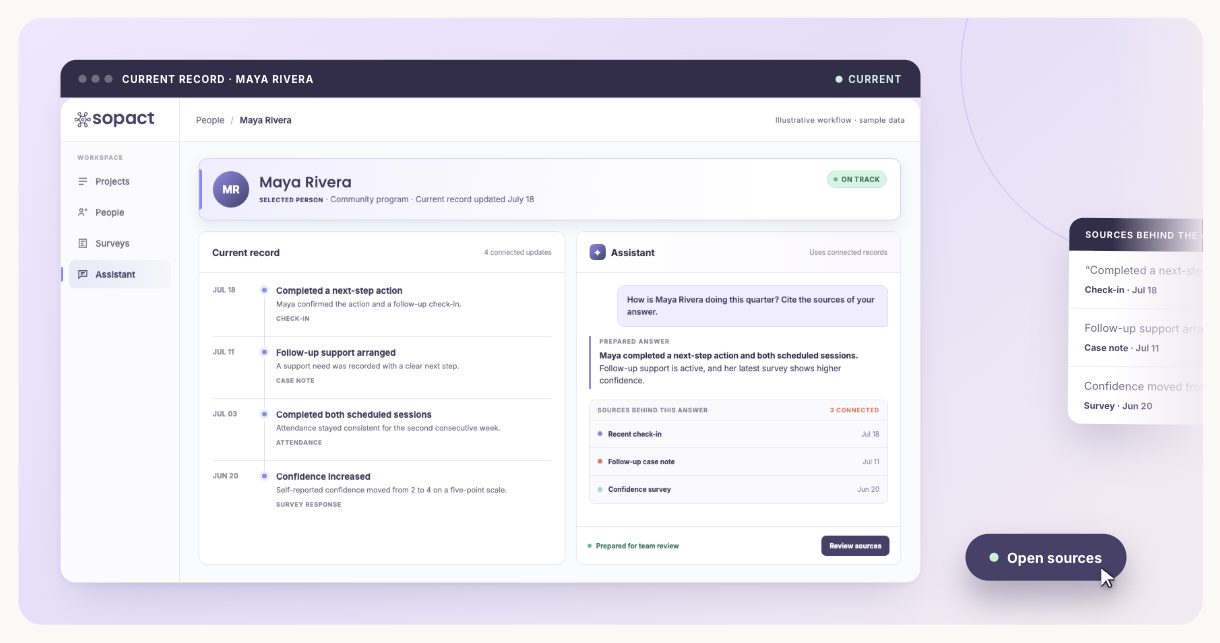
One person. A survey, a note, an attendance record and a check-in, all on one record — and an answer that shows which ones it used.
Why teams are doing this themselves now
For years, “we need to look at this properly” meant hiring someone. A consultant for the annual evaluation. An analyst for the dashboard. An agency for the report.
That is changing, and not because budgets got bigger. Reporting stopped being an annual event — people ask for things all year, and a consultant cannot answer a question that turns up on a Tuesday. The part that convinces anyone is no longer the number; it is what someone wrote, or what is inside a case note. And the questions became longitudinal: not “what is the average score” but “what changed for these people since last year, and why.”
So teams want to run it themselves. Not because doing it yourself is trendy, but because waiting has got too expensive. Below are the eight things that decide whether you actually can — and who does each one well today.
The eight things that decide it
1. Self-driven — your team can run it
The question is not how powerful the software is. It is who has to touch it. If sending a follow-up survey, adding a question or pulling one group of people needs a trained admin, a stats background or a ticket to IT, then every answer still goes through one person. You have moved the queue, not removed it.
Having a specialist run it is a fair trade if you are a global company with a research team. It is a bad trade for a team of fifteen.
Who does this well
SurveyMonkey — easiest of the group to run yourself, and the shallowest, so there is less to ask of it.
Qualtrics — can do almost anything, and usually comes with a person whose job is running it.
Alchemer — in between; the clever logic that makes it worth buying is still technical work.
Sopact — built around this. Someone on the programme team sends the next wave and pulls a group without asking for help.
2. One record per person
Most organisations do not have a survey problem. They have six systems: a survey tool, a spreadsheet of applications, an intake form, a folder of case notes, an attendance sheet, and somebody's inbox. Each is fine on its own. Together they turn the simplest question — what happened to this person — into a small project.
What matters is whether all of that ends up on one record per person, or stays as six files someone has to match up by hand. Matching by hand happens once, in a rush, and never gets repeated.
Who does this well
Nobody in this group, and it is worth saying plainly.
Qualtrics, Alchemer, SurveyMonkey, QuestionPro, Typeform — all built around the survey, not the person. Applications, case notes and attendance stay somewhere else.
Qualtrics has the most connectors, which shortens the export but does not do the matching for you.
Sopact — everything lands on one record per person. It is the only reason the rest of this list works.
3. Volume — it reads all of it, not a sample
A person can read about two hundred open-ended answers before they start skimming. Past that, teams read a sample — and a sample is where the awkward findings go missing, because the answers nobody reads are usually the angry ones and the ones from people who dropped out.
This is not about big numbers for their own sake. It is the difference between something you can stand behind and something you happened to notice.
Who does this well
All of them collect at volume — that stopped being hard a decade ago. Reading is where it splits.
Qualtrics Text iQ — handles a lot of response text.
SurveyMonkey, QuestionPro, Typeform — a summary, then it is a person's job. In practice that caps at a few hundred.
ChatGPT / Copilot — less consistent the more you give them at once.
Sopact — every answer and every document read as it arrives, so there is no sampling step.
4. Longitudinal — it finds the same person next year
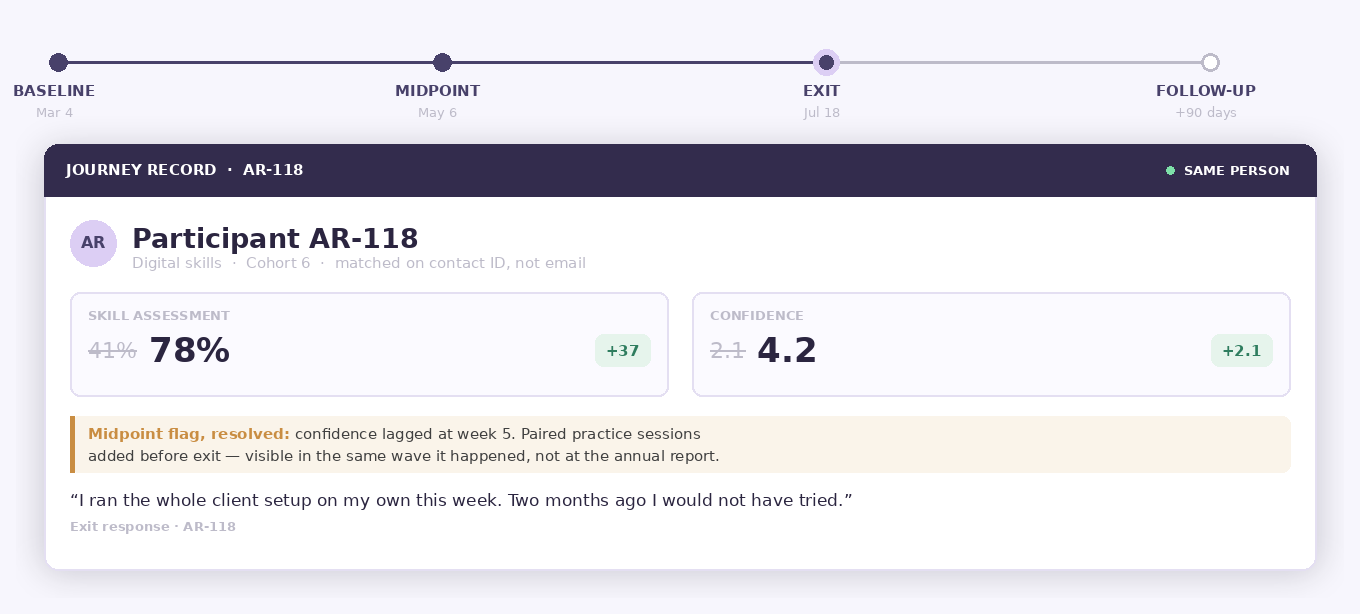
You cannot show change without the same person twice. That is what longitudinal means in practice, and it is a data-model question, not a survey-design one: if a tool makes a separate file for every wave, then showing change means matching people across files — usually on an email address that has changed. And the people whose email changed are the ones whose lives changed most.
The usual workaround is asking respondents to remember an ID. They don't. One research lead put it simply: people “enter something different the second time, and we can't match them.” A match rate around 60% is normal, and the missing 40% is never a random 40% — so the trend you end up reporting is the trend among the people whose lives stayed stable.
Who does this well
Qualtrics — does it properly, through panels and embedded data. Takes someone who knows how to set it up.
Alchemer — on the more expensive plans only.
SurveyMonkey — not at all. Every survey is its own file.
ChatGPT / Copilot — cannot. They have no idea who anyone is.
Sopact — a contact ID assigned the first time you reach someone; every later wave writes to it, so nobody is asked to remember anything.
5. Qualitative — it reads what people wrote
The score tells you what happened. The comment underneath tells you why, and the why is the part anyone acts on. Nearly every tool stores open-ended answers. Far fewer read them, and the ones that do usually read them months later, when the thing being described is over.
Two things matter. You should be able to see the actual quotes behind every theme, so you can check it instead of trusting it. And it should happen as answers arrive — a reason you learn in week two is a decision, the same reason in month nine is a footnote.
Who does this well
Qualtrics — reads open-ended answers properly through Text iQ, which is a separate line on the quote.
Alchemer — asks smart follow-up questions during the survey. Useful, but a different job.
SurveyMonkey — summarises. QuestionPro — basic text analytics.
ChatGPT / Copilot — read well, but give you a different set of themes on a different day.
Sopact — themes each answer as it lands and shows the quote behind every theme.
6. Documents — it reads your files too
This is the gap almost nobody checks for, and it is the biggest one. You collect far more than survey answers: case notes, uploaded reports, applications, plans, transcripts. In every one of these survey tools, those are just attachments — stored, findable by filename, and unread.
Software that reads survey answers does not read documents. That sounds like a small difference and it isn't. If a third of what a funder wants to know is inside a hundred case notes, a tool that only reads response text cannot answer the question at all, and someone ends up opening files one by one.
Who does this well
Nobody in the survey category. This is the widest gap of the eight.
Qualtrics Text iQ — reads survey answers, not the PDF somebody uploaded.
Alchemer, SurveyMonkey, QuestionPro, Typeform — documents are attachments.
ChatGPT / Copilot — will read whatever you paste in, but nothing sticks and nothing connects to a person.
Sopact — reads documents the same way it reads answers, and what it pulls out lands on that person's record.
7. Assistant — anyone can ask a question
The alternative to a dashboard is not a better dashboard. It is that the regional director asks about her own region, in plain language, and gets an answer back with the records it used underneath it. Nobody queues.
A dashboard answers a fixed set of questions someone chose in advance, and the question you need is almost always the one nobody thought of. Being able to just ask is what lets a small team behave like a big one. It also means permissions have to cover the answers, so nobody can ask their way into something they shouldn't see.
Who does this well
Qualtrics and SurveyMonkey — both have AI chat over their own results. It is real, and it stops at their own survey data.
Alchemer, QuestionPro, Typeform — dashboards and exports.
ChatGPT / Copilot — answer anything, with no permissions and nothing behind the answer.
Sopact — answers across everything on the record and lists the records it used.
8. Reliable — reproducible and traceable
This is the one that decides whether any of the rest is usable, and it is usually checked last. Two words are worth using with a vendor. Reproducible: ask the same question twice and get the same number. Traceable: click from any number to the actual answers behind it. An answer that is neither is not evidence — you cannot put it in a board pack or a funder report, and you will find that out at the worst moment.
It is why general AI tools fall down here, even though they read well. A data lead at a large food bank described trying it with Copilot: it “produces inconsistent results. The same input can yield different answers on different runs, making it hard to trust the output… or present a defensible picture to the executive team.” Studies have measured them getting sources wrong 28% to 40% of the time.
The fix is in how it is built, not in a better model. Counts, averages and filters run as ordinary database queries — deterministic, meaning the same question returns the identical number every time. AI is used only where language has to be read.
Who does this well
Qualtrics, Alchemer, SurveyMonkey, QuestionPro, Typeform — the numbers are solid, because a count is a count.
What is harder to check is their AI text output — none of them routinely show you the answers behind a theme.
ChatGPT / Copilot — fail on both: a different answer on a different day, and no way to see how they got there.
Sopact — numbers stay deterministic, AI is used only to read language, and every figure links back to the answer or passage it came from.
Where each one stops
Read down the eight and the pattern is clear: these tools are strong at collecting and thin on everything after it. Same conclusion, shorter.
Best at, and where it stops
Tool
Best at
Where it stops
Qualtrics
The strongest survey engine there is — logic, panels, governance. Longitudinal done properly (4) and real text analytics (5)
Needs a specialist (1). Text iQ reads answers, not documents (6). Nothing joins up around a person (2)
Alchemer
Clever survey logic without enterprise pricing. Smart follow-up questions mid-survey
Longitudinal only on higher plans (4). No document reading (6). Nothing to ask (7)
SurveyMonkey Enterprise
Easiest to run yourself (1). Fine for lots of straightforward surveys
A separate file per wave (4). Summarises rather than reads (5). No documents (6)
QuestionPro / Typeform
Good forms, quick to send, low friction
Built around the form — thin or missing on (2), (4), (5), (6), (7)
ChatGPT / Copilot
Reads anything you paste in, documents included (6). Nothing to buy
No identity (4), no permissions (7), not reproducible (8)
Sopact Sense
Built for what comes after collecting: one record per person (2), a contact ID that survives every wave (4), answers and documents read on arrival (5, 6), ask in plain language and see the sources (7), reproducible and traceable (8)
Not the survey engine Qualtrics is. It answers when asked — it is not a screen that updates by itself
Qualtrics deserves the fair word: if you run customer or employee experience at global scale and have a team to operate it, it is the right choice and nothing here changes that. The rest of this page matters when the same people come back, when what they wrote carries the meaning, and when the person who needs the answer is not the person who can produce it.
Can I keep what I have and add to it?
Usually, yes. Plenty of organisations keep their current tool for what it does well and add something for the parts it doesn't cover, passing results on to a warehouse or BI tool through an API. It is rarely a rip-and-replace.
One honest limit: if you need a live screen that updates on its own without anyone asking, that is a BI tool's job. Sopact answers when asked.
Common questions
What is the best enterprise survey software in 2026?
It depends on the job. Qualtrics is the strongest survey engine if you have a team to run it. Alchemer gives you clever logic for less. SurveyMonkey Enterprise is the simplest at scale. If your work is longitudinal and qualitative — the same people over years, and what they wrote and uploaded actually read — that is a different kind of tool, and Sopact Sense is built for it.
Does Qualtrics analyse open-ended responses?
Yes, through Text iQ, which is sold separately from the base licence. It reads what people type into a survey. It is not built to pull information out of uploaded documents like case notes, reports or plans.
Can these tools follow the same person across waves?
Some can, with setup. Qualtrics does it properly through panels and embedded data; Alchemer keeps it on higher plans. SurveyMonkey makes a separate file per survey with no built-in way to connect respondents across them. The real question is whether identity is built in at collection or reconstructed later by matching exports.
Why not just use ChatGPT or Copilot on our exports?
They are useful for a first look. They are not reliable for a number you have to defend: the same question can come back different on a different day, they can't show you which records they used, and they have no idea that two rows are the same person.
What should we ask about security?
Single sign-on, permissions by role, an audit trail, and where the data is stored. One thing people forget: if staff can ask questions of the data directly, permissions have to cover those answers too.
Do we have to replace what we have?
No. Most organisations keep what works and add something for the parts that don't, connecting the two through an API.