Data Collection Sources: Improving Primary and Secondary Data Workflows
Build and deliver a rigorous data collection system from both primary and secondary sources in weeks, not years. Learn step-by-step workflows, use cases, and AI tools that make your data clean, connected, and analysis-ready with Sopact Sense.
Why Traditional Data Collection Sources Fail
80% of time wasted on cleaning data
Data teams spend the bulk of their day fixing silos, typos, and duplicates instead of generating insights.
Disjointed Data Collection Process
Hard to coordinate design, data entry, and stakeholder input across departments, leading to inefficiencies and silos.
Lost in Translation
Open-ended feedback, documents, images, and video sit unused—impossible to analyze at scale.
Reinventing Data Collection: Smarter, Faster, Connected
Author: Unmesh Sheth — Founder & CEO, Sopact Last updated: August 9, 2025
Data collection today demands more than checkboxes and spreadsheets. It requires a smarter system that adapts to your context, integrates across touchpoints, and delivers high-quality insights—fast. Sopact offers a dynamic, AI-native approach to unify your most critical data collection sources into one seamless workflow. ✔️ Collect data from surveys, interviews, documents, and custom forms—all in one place ✔️ Automate thematic, sentiment, and scoring analysis across structured and unstructured inputs ✔️ Engage stakeholders with real-time collaboration, correction workflows, and linked responses
“Organizations waste 60% of their time cleaning and reformatting data that should’ve been collected right the first time.” – World Economic Forum, 2023
Whether you're running a training program, impact evaluation, or workforce upskilling initiative, modern data collection must start with intelligent design—and end with analysis that drives action.
What Is a Data Collection Source?
A data collection source refers to any channel or method through which you capture information from stakeholders. This can range from digital forms and interviews to third-party databases or uploaded reports.
“The richness of your analysis is directly tied to the diversity and reliability of your data sources.” – Sopact Team
⚙️ Why AI-Driven Data Collection Sources Are a Game Changer
Traditional methods treat data collection and analysis as separate steps. This often means waiting days—or weeks—to clean, tag, and extract insight from feedback, documents, or survey responses. AI-native tools change the equation entirely:
Analyze open-text, file uploads, and responses in real time
Spot incomplete entries, missing answers, or red flags before the data hits your dashboard
Trigger auto-reminders or clarification links for respondents
Seamlessly integrate with Google Sheets, BI tools, and APIs for real-time flow
This isn’t just automation. It’s a connected ecosystem built for continuous improvement and responsive decisions.
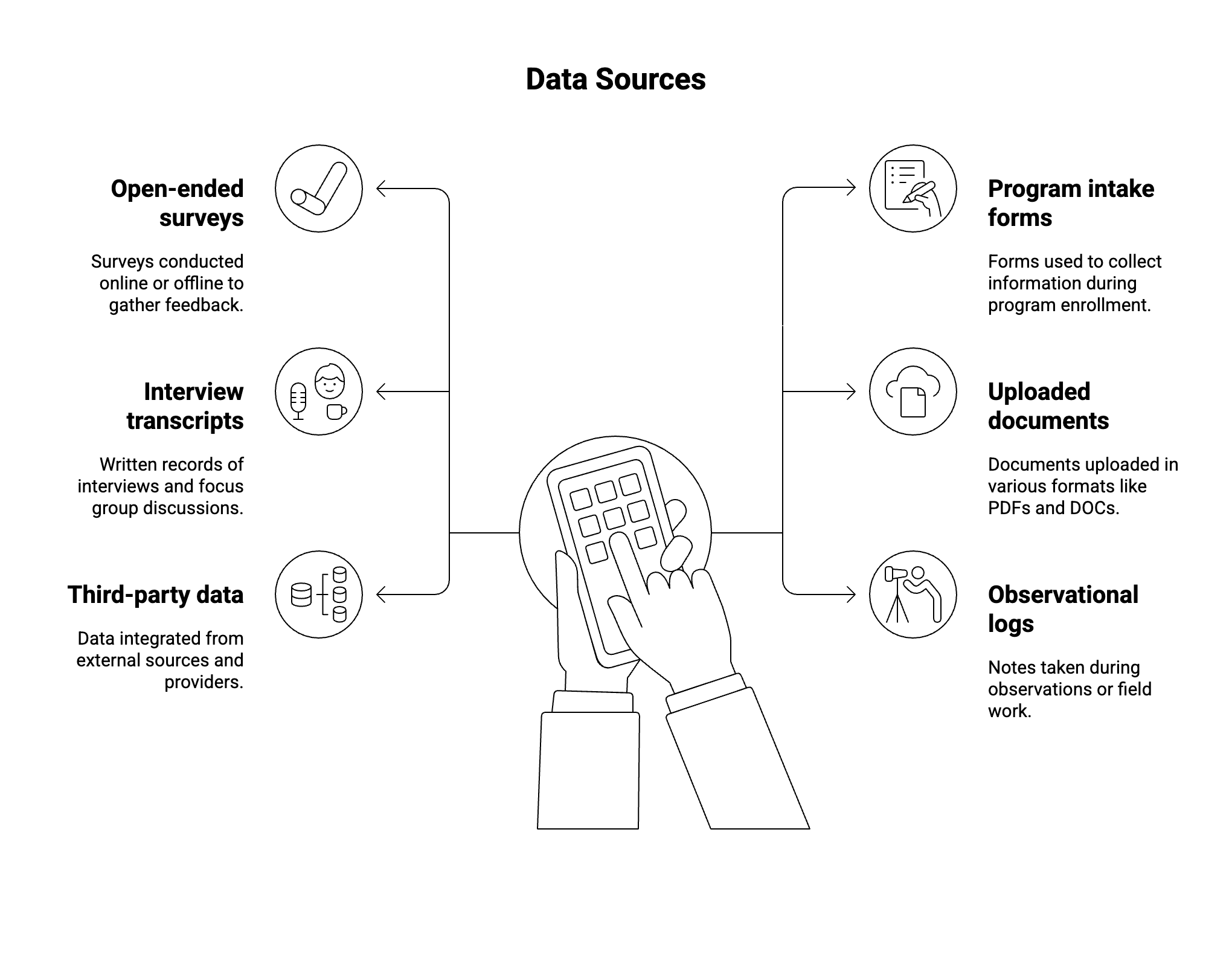
What Types of Data Collection Sources Can You Use?
Open-ended surveys (online or offline)
Program intake and onboarding forms
Interviews and focus group transcripts
Uploaded documents (PDFs, DOCs, etc.)
Third-party data integrations
Observational logs or field notes
Types of Data Collection Sources
What Can You Find and Collaborate On?
Critical insights by stakeholder, location, or program type
Missed responses or empty fields flagged automatically
Confidence scoring across qualitative answers
AI-driven rubrics to verify alignment with program goals
Gap detection for report compliance or grant evaluation
Automatically generated summaries and narrative reports
Stakeholder-linked data trails for longitudinal tracking
Real-time collaboration without exporting or email chains
What’s the difference between primary and secondary data sources?
Data sources fall into two categories:
Primary data: collected firsthand by an organization through surveys, interviews, observations, experiments, etc.
Secondary data: collected by others, including government reports, market research, academic literature, and internal records.
In theory, both should yield insights. In practice, most organizations waste over 80% of their time cleaning data because their systems don’t talk to each other or track data lineage across forms.
Sopact Sense flips the script by linking data directly to people using unique IDs, keeping everything connected across time and touchpoints.
What are examples of primary data sources?
Surveys
Used for feedback, assessments, registration, or intake. But generic survey tools create fragmented, duplicative data.
Sopact Sense Difference:
Built-in skip logic and validation
Branded experiences
Unique links per respondent prevent duplication
Forms are always tied to Contacts, not just anonymous responses
Interviews
Structured, semi-structured, or open-ended conversations. Often hard to analyze at scale.
Sopact Sense Difference:
Transcripts or notes can be analyzed using Intelligent Cell
Themes and sentiment surfaced automatically
Rubric scoring applied instantly for consistency
Observations
Direct monitoring of behavior or activities. Data often collected in notebooks or spreadsheets.
Sopact Sense Difference:
Field observations uploaded via mobile-friendly forms
Qualitative analysis engine processes free text or attached docs
Insights stored and linked back to individuals or groups
Experiments
Controlled conditions to test hypotheses. Data often collected separately from CRM or feedback tools.
Sopact Sense Difference:
Form responses tied to cohort or intervention group
Validation rules prevent entry errors
Real-time dashboards track outcomes across groups
Focus Groups
In-depth conversations across small groups. Rich but unstructured data.
Sopact Sense Difference:
Input PDFs or transcripts, analyze instantly
Tag themes and participant sentiment
Generate BI-ready output for comparison across sessions
Case Studies
Narrative-rich documentation of programs, partners, or individuals.
Sopact Sense Difference:
Upload case reports or PDFs
Intelligent Cell extracts patterns across documents
Data is not siloed—linked to stakeholders and programs
Combine with survey data for full journey analysis
Government & Public Data
Census, labor market info, or public health statistics.
Sopact Sense Difference:
Use as benchmarking in dashboards
Tag and compare alongside primary data
Published Literature or Research Reports
Includes third-party evaluation findings or academic studies.
Sopact Sense Difference:
Upload PDFs and auto-analyze
Score against your evaluation rubric
Extract key takeaways for strategic insights
Market Research Reports
From consulting firms, funders, or sector networks.
Sopact Sense Difference:
Combine insights with survey or application data
Use AI to categorize trends for competitive analysis
Online & Social Data
Includes scraped text, public reviews, or web comments.
Sopact Sense Difference:
Paste into forms or upload CSVs
Analyze themes instantly
Compare with structured inputs in one dashboard
How does Sopact Sense improve data collection across the board?
1. Unique IDs for every contact
No more duplicate records. Every response—past or future—is linked to a real person.
2. Relationships between contacts and forms
Track stakeholder journeys over time. Intake, midline, post—connected automatically.
3. Real-time data correction
Stakeholders can update inaccurate info via secure links—no spreadsheets needed.
4. Qualitative insights on demand
Intelligent Cell turns open-ended answers and attachments into clean, summarized, rubric-scored data.
5. Integration-ready from day one
Export clean data to Looker, Power BI, or Sheets. No post-hoc cleanup or merging.
Why does this matter?
Without clean primary and secondary data, dashboards are misleading and decisions are delayed. Sopact Sense gives you:
Instant feedback loops
Clean datasets for every round of collection
Automated analysis and scoring
It’s not just another form tool. It’s your clean-data infrastructure for surveys, documents, and decision-making at scale.
Data Collection Sources — Frequently Asked Questions
Q1
What counts as a “data collection source” in impact work?
Any channel that captures evidence you can trust and reuse: structured forms/surveys, program/admin systems (CRM, SIS, HRIS, case management), documents/PDFs, interviews and focus groups, emails and helpdesk logs, SMS/IVR, kiosks or tablets, sensors/IoT, web analytics, and third-party/open datasets (census, labor, health, climate, GIS).
Q2
Which sources are most reliable for outcome measurement?
Use a mixed stack: admin systems for verified events (attendance, completion), structured surveys for perception/experience (confidence, readiness), and qualitative evidence for the “why.” When all three link to the same unique ID and timepoint, you get defensible change stories—not just activity counts.
Q3
How do we choose the right sources without over-collecting?
Work backward from decisions. For each decision, list the minimum signals needed and the cadence (real-time, weekly, checkpoint). Prefer existing admin/system data first; add short pulse questions only where context is missing. Sunset any source that doesn’t drive a decision or quality improvement.
Q4
How do we unify data coming from many sources?
Establish one unique ID per person/org/site, consistent constructs, and a shared codebook. Enforce typed fields, stable option keys, range checks, and dedup at submit. Store metadata (cohort, site, instrument version, timepoint). Use mapping tables for legacy codes so apples-to-apples comparisons hold over time.
Q5
What if we work in low-connectivity or offline settings?
Offer SMS/USSD/IVR options, enumerator-mode on tablets with offline sync, QR codes for quick returns, and scanned paper forms with validation on import. Use secure unique links so updates overwrite the same record instead of creating duplicates.
Q6
How do we capture qualitative sources (interviews, PDFs) at scale?
Accept uploads/transcripts and tie them to the same ID and timepoint as surveys/admin data. Sopact’s Intelligent Cell extracts summaries, themes, sentiment, and rubric scores; Intelligent Row generates per-entity briefs; Intelligent Column links themes to outcomes for driver analysis you can act on.
Q7
Real-time vs. periodic collection—how do we decide?
Use real-time (webhooks, sensors, incident intake) for risks and operations; use periodic checkpoints (pre/mid/exit/follow-up) for outcomes and learning. Keep constructs consistent so trends are comparable, then layer light pulses when decisions are time-sensitive.
Q8
How do we keep data clean and AI-ready at the source?
Typed fields, validations, reference lookups, range checks, and dedup at submit; versioned instruments; consent capture; and required metadata (timepoint, cohort, site). Clean-at-source pipelines eliminate brittle ETL and make analytics/models trustworthy from day one.
Q9
Can we integrate external systems and spreadsheets safely?
Yes—via APIs/webhooks, scheduled imports, SFTP, or one-click spreadsheet uploads with schema checks. Use stable IDs and taxonomies so records map correctly. Apply role-based permissions, retention/export policies, and audit logs to keep everything traceable and compliant.
Q10
How do we handle privacy, consent, and sensitive sources?
Capture informed consent at intake; minimize PII; mask sensitive fields; encrypt in transit & at rest; and keep reviewer-only notes separate. Maintain an audit trail (who changed what, when) and document data lineage so every metric can be traced back to source evidence.
Q11
How do we measure ROI of a new source?
Track setup cost and maintenance effort vs. decision impact: time-to-insight, actions taken, outcome lift by segment, and reduced reconciliation/duplicate rates. Keep a 90-day review—keep, fix, or retire—and promote only high-value fields into your canonical schema.
Q12
How does Sopact support diverse data collection sources end-to-end?
Sopact centralizes forms, uploads, APIs, spreadsheets, sensors, and third-party data under unique IDs. Intelligent Grid compares cohorts/timepoints; Intelligent Column aligns drivers with outcomes; living reports replace static PDFs—so teams move from months of cleanup to minutes of action.
Time to Rethink Data Collection Sources for Today’s Need
Imagine data collection that evolves with your needs, keeps every record linked and error-free, and turns messy text or PDFs into insights instantly—no cleaning required.
AI-Native
Upload text, images, video, and long-form documents and let our agentic AI transform them into actionable insights instantly.
Smart Collaborative
Enables seamless team collaboration making it simple to co-design forms, align data across departments, and engage stakeholders to correct or complete information.
True data integrity
Every respondent gets a unique ID and link. Automatically eliminating duplicates, spotting typos, and enabling in-form corrections.
Self-Driven
Update questions, add new fields, or tweak logic yourself, no developers required. Launch improvements in minutes, not weeks.
FAQ
Find the answers you need
Add your frequently asked question here
Add your frequently asked question here
Add your frequently asked question here
*this is a footnote example to give a piece of extra information.