What is AI-native grant management?
AI-native grant management is a system that reads every application, reference, and grantee report against your rubric the moment it arrives, on one persistent applicant record — the Application Thread — that keeps collecting after the award. Grant software with AI features bolts a chatbot onto a system that still only stores and routes forms. Sopact is built AI-native, so reading the content is the default, not an add-on.
The pain is familiar. As one funder put it, “I already have my grant system, but I don’t really get the outcome.” Applications get routed to reviewers but never actually read against the criteria; a score lives in one reviewer’s head; and the grantee record effectively dies at close-out, so next year’s cycle starts blind. The software moved the paper. It never read it.
Key takeaways
- AI-native grant management reads every application against your rubric on arrival; grant software with AI features bolts a chatbot onto a form store that still just routes and stores. Sopact is built AI-native on the Application Thread.
- The test that separates the two: does the system read each application on arrival, or store it and summarize on demand? Sopact reads on arrival and cites the exact sentence behind every score.
- The Application Thread is one persistent applicant record where every application, reference, and grantee report lands and keeps collecting after the award, so this cycle sharpens the next instead of starting blind.
- AI grant review in Sopact drafts a score for every rubric criterion with the evidence quoted, screens eligibility on arrival, and surfaces reviewer bias across a round, while a human still decides.
- Sopact calls reading on one persistent record grant intelligence: the applicant’s history informs the decision, not just the form in front of you.
AI-native grant management vs grant software with AI features
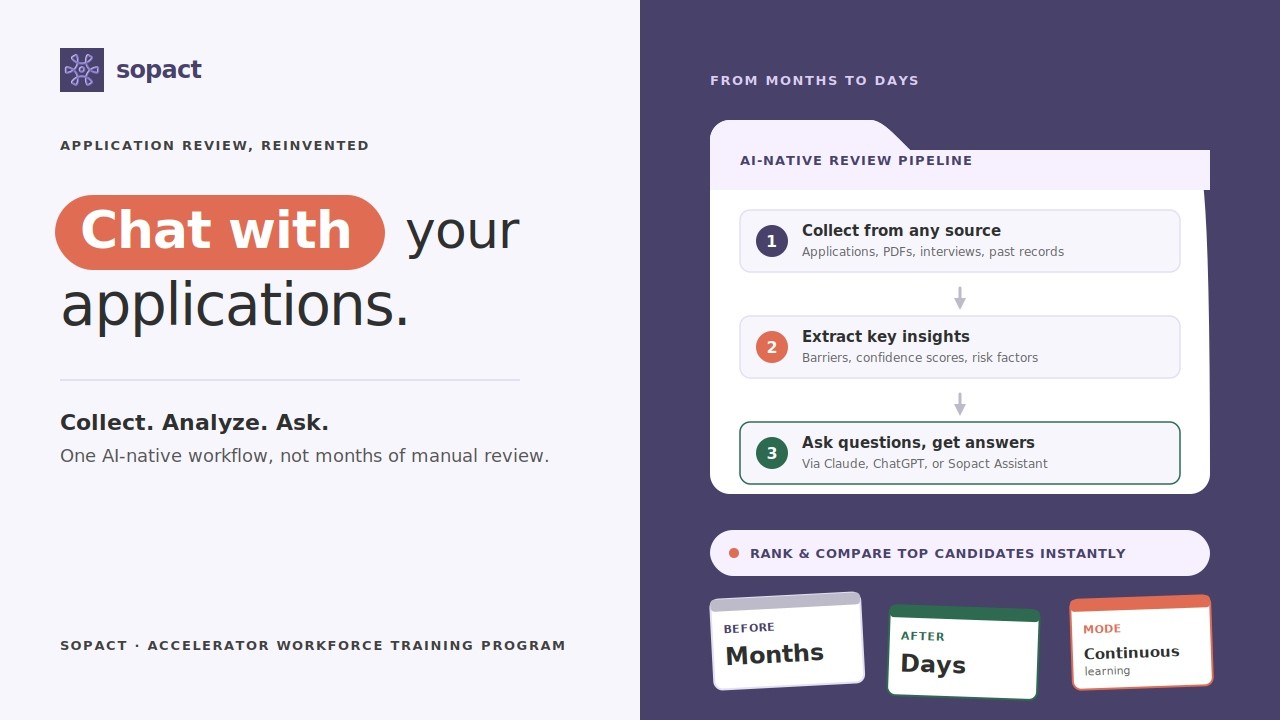
The one test is simple: does the system read every application against your rubric the moment it lands, or does it store the form and let a chatbot summarize it later when someone asks? Grant software with AI features keeps the old data model, a form store with routing, and adds a summarizer on top. AI-native grant management inverts the default: reading happens on arrival, on one persistent applicant record.
That distinction is a data-model choice, not a feature toggle. A chatbot bolted onto a form store can summarize a document you point it at, but it does not change what the system is built to do, which is store and route. Sopact reads each application, reference, and report against the rubric as it arrives and keeps it on the Application Thread, so the reading compounds across a cycle instead of being requested one document at a time. See the head category on grant management software.
How AI grant review works
AI grant review means the system reads each application against your scoring rubric on arrival and drafts a score for every criterion with the exact sentence from the application quoted as evidence, so a human confirms or overrides a draft instead of starting from a blank scorecard. Sopact runs AI grant review on the Application Thread, which is why a whole batch can arrive already scored and ranked.
Because every application in a round is read the same way, Sopact can screen eligibility before a reviewer spends time on a file, theme a whole round to show what applicants are actually asking for, and surface where one reviewer scores consistently harder than the rest. That is the review-stage depth on grant application review.
How grant software evolved — and the one test
Grant management software grew up around the request. The first generation digitized the paper application and the approval workflow: request in, review, approve, disburse. Systems like Blackbaud’s GIFTS, Fluxx, SmartSimple, Foundant, Submittable, and Bonterra’s CyberGrants are mature, capable versions of that idea, with strong intake forms, reviewer routing, payment tracking, and compliance records. At the category level they are request-centric and workflow-centric, built to move a grant from application to disbursement.
None of that was wrong; it was the problem of its era. What those systems were never built to do is read the content of an application, a reference, or a grantee report, and keep reading it after the award. So the one test that separates the eras is this: hand the system a batch of applications and ask it to score each against your rubric with the evidence quoted. A workflow tool returns an organized queue; an AI-native system returns a scored, evidenced batch. Compare the field on best grant management software.
What you can actually do with it
Concretely, that means you can review 500 applications in the time it takes to read a few, each with a draft score and the sentence behind it; ask a plain question across every document in a grant and get an answer traced to its source; generate a board report from grantee reports that already sit on the same applicant IDs; and catch a compliance gap or a budget-variance flag before the award goes out rather than at the audit. For funders running many small grants, that reach matters — see nonprofit grant management and grant software for foundations.
This is what Sopact calls grant intelligence: the applicant’s whole history on the Application Thread informing each decision, not just the form in front of you.
How do I choose AI grant management software?
Choose AI grant management software by one test: does it read every application against your rubric on arrival and keep the record after close-out, or does it store forms and summarize on demand? An AI-native platform reads content as its default; grant software with AI features adds a chatbot to a form store. The table below sets the two data models side by side.
Legacy grant software vs AI-native, by the questions worth asking
| The question to ask | Legacy grant software | AI-native (Application Thread) |
|---|
| Reads applications on arrival? | No, it stores and routes | Yes, against your rubric |
| Record after close-out? | Effectively ends | Keeps collecting |
| Who changes a form or rubric? | IT or a consultant | You, in the tool |
| How the impact report is made? | Re-typed from PDFs | A query over the record |
| What it’s built to do best? | Move the workflow | Read the content |
See the head page on grant management software and the review depth on grant application review.
A scorecard tells you who won. The Loop tells you in time to fix the rubric.
A rubric that scores the wrong thing is worth catching in week one of a cycle, not in the debrief after the decisions are made. The value of reading applications against the rubric is highest while the cycle is still open, when a biased criterion or an inconsistent reviewer can still be corrected. That is the premise of the Loop, Sopact’s method for continuous intelligence: collect clean at the source, analyze the moment an application arrives, improve while the cycle can still be changed.
The Loop is also what makes a decision defensible: every score traces back to the rubric line and the sentence in the application it came from, the standard detailed in Loop traceability, so a shortlist or a rejection rests on the applicant’s own words rather than a reviewer’s memory.
One method, three moves that never stop
1 · CollectClean at the source; every application, reference, and score lands on one applicant record.
2 · AnalyzeOn arrival; each application read against the rubric as it lands, with the evidence cited.
3 · ImproveIn time to act; a biased or inconsistent rubric surfaces mid-cycle, while it can still be fixed.
Then the cycle runs again, a little sharper each time. Read the method: the Loop methodology →
Run AI grant review on your own applications this week
The fastest way to judge AI grant management software is to make it read your own applications. Export a batch with your rubric, then paste the prompts below into Sopact Sense’s Assistant, or reason through them with your team. The arrow above each prompt links the Academy walkthrough with the expected output and tips.
Academy walkthrough → Analyze a batch of applications
Here is a batch of applications for one cycle: [ATTACH]. Read each against our rubric as it lands, draft a score for every criterion with the exact sentence from the application quoted as evidence, flag any that miss an eligibility rule, and rank the batch so I can see the shortlist and why each applicant sits where it does on the Application Thread.
Academy walkthrough → Score a proposal against the rubric
Here is one proposal and our scoring rubric: [ATTACH]. Score each rubric criterion, quote the sentence in the proposal that supports the score, and mark any criterion where the evidence is thin, so a reviewer can confirm or override the draft rather than start from a blank scorecard.
Academy walkthrough → Screen applications for eligibility
Here are our eligibility rules and a batch of applications: [ATTACH]. Read each application against every rule on arrival, mark it eligible or ineligible with the exact rule and the sentence that decided it, and list the borderline ones so a human makes the call before any reviewer time is spent.
Academy walkthrough → Extract outcomes from a grantee report
Here is a grantee’s narrative and financial report for this period: [ATTACH]. Read it against the logframe we funded, pull each outcome with the exact sentence from the report quoted as evidence, separate what they spent from what changed, and flag any indicator the report does not answer, so I get outcomes from the document I already have on the same record.
Learn the how-to in the Academy
Each walkthrough is short and practical: what to do, the prompt to run, the output to expect, and the tips that keep it reliable.
Watch: AI grant review reading applications against the rubric on arrival, with every score traced to its evidence on the Application Thread.
Frequently asked questions
What is AI grant management software?
AI grant management software manages the grant lifecycle — intake, review, award, and reporting — with AI that reads application content, not just a chatbot layered on a form. Sopact is AI-native grant management software: it reads every application against your rubric on arrival on the Application Thread.
What is AI-native grant management?
AI-native grant management is a system where reading is the default: every application, reference, and grantee report is read against your rubric the moment it arrives, on one persistent record. Sopact’s Application Thread keeps that record collecting after the award, so grant intelligence builds over time.
Is AI-native grant management different from grant software with AI features?
Yes. Grant software with AI features keeps a form-store data model and adds a chatbot; AI-native grant management reads content on arrival as its default. Sopact reads each application against the rubric as it lands rather than summarizing a stored form on demand.
How does AI grant review work?
AI grant review reads each application against your scoring rubric on arrival and drafts a score for every criterion with the sentence from the application quoted as evidence. Sopact runs AI grant review so a human confirms or overrides a draft instead of scoring from a blank scorecard.
What is the best AI grant management software?
The best AI grant management software is the one that reads every application against your rubric on arrival and keeps the record after close-out, not the one with the most workflow settings. Judge Sopact by handing it a batch and asking for scored, evidenced results on the Application Thread.
Does Sopact replace my grant management system?
Not necessarily. Many funders keep their system of record and add Sopact for the reading it does not do. Sopact reads applications and grantee reports on the Application Thread, so it can work as an “AND” alongside a tool like CyberGrants rather than a rip-and-replace.
Can AI review grant applications fairly?
AI grant review is fairer when every application is read the same way against the same rubric with the evidence cited and a human makes the call. Sopact drafts scores with the deciding sentence quoted and surfaces where one reviewer scores harder than the rest, so bias is visible rather than hidden.
How is grant intelligence different from grant management software?
Grant management software moves a grant from application to disbursement; grant intelligence reads the content and keeps the record. Sopact’s grant intelligence lives on the Application Thread, so the applicant’s history informs each decision instead of ending at close-out.
Next: see the head category on grant management software, or the review depth on grant application review.
Read, not just routed
01CollectEvery application, one record
02Read on arrivalAgainst your rubric
03Review & scoreEvidence quoted
04ReportA query over the record
AI-native grant management reads every application on arrival, not just routes it.