
Time to Rethink Data Design for the AI Era
Imagine a data system that evolves with your needs, keeps records pristine from the first entry, and produces AI-ready datasets in seconds—not months.
Create clean, connected data pipelines designed for AI from day one. Learn step-by-step guidelines, tools, and real-world examples—plus how Sopact Sense ensures your data is always AI-ready without endless cleanup.
Everyone wants AI.
But most teams forget the critical first step: data that’s structured, complete, and ready for learning.
Without it, AI models give vague insights—or worse, reinforce bias.
✔️ Clean and structure data across open-text, documents, and surveys
✔️ Identify and fix gaps at the source with real-time collaboration
✔️ Transform qualitative input into AI-ready training sets, scores, or summaries
“Data scientists spend 80% of their time preparing data and only 20% analyzing it.” —Forbes Data & AI Survey 2023
Data for AI refers to the process of collecting, cleaning, and transforming raw inputs—especially unstructured text—into formats that AI can learn from and act on.
In Sopact, that means connecting qualitative feedback to quantitative models, without losing nuance or voice.
“AI is only as good as the feedback it learns from. Sopact ensures that feedback is real, complete, and ready to scale.” – Sopact Team
Typical tools gather responses.
But Sopact doesn’t stop there—it prepares your entire ecosystem for AI-readiness, automatically.
No more waiting months to "clean the dataset."
You’re ready to train and deploy smarter models—today.
When your data is AI-ready, your decisions become insight-ready.
Sopact is where that transformation begins.
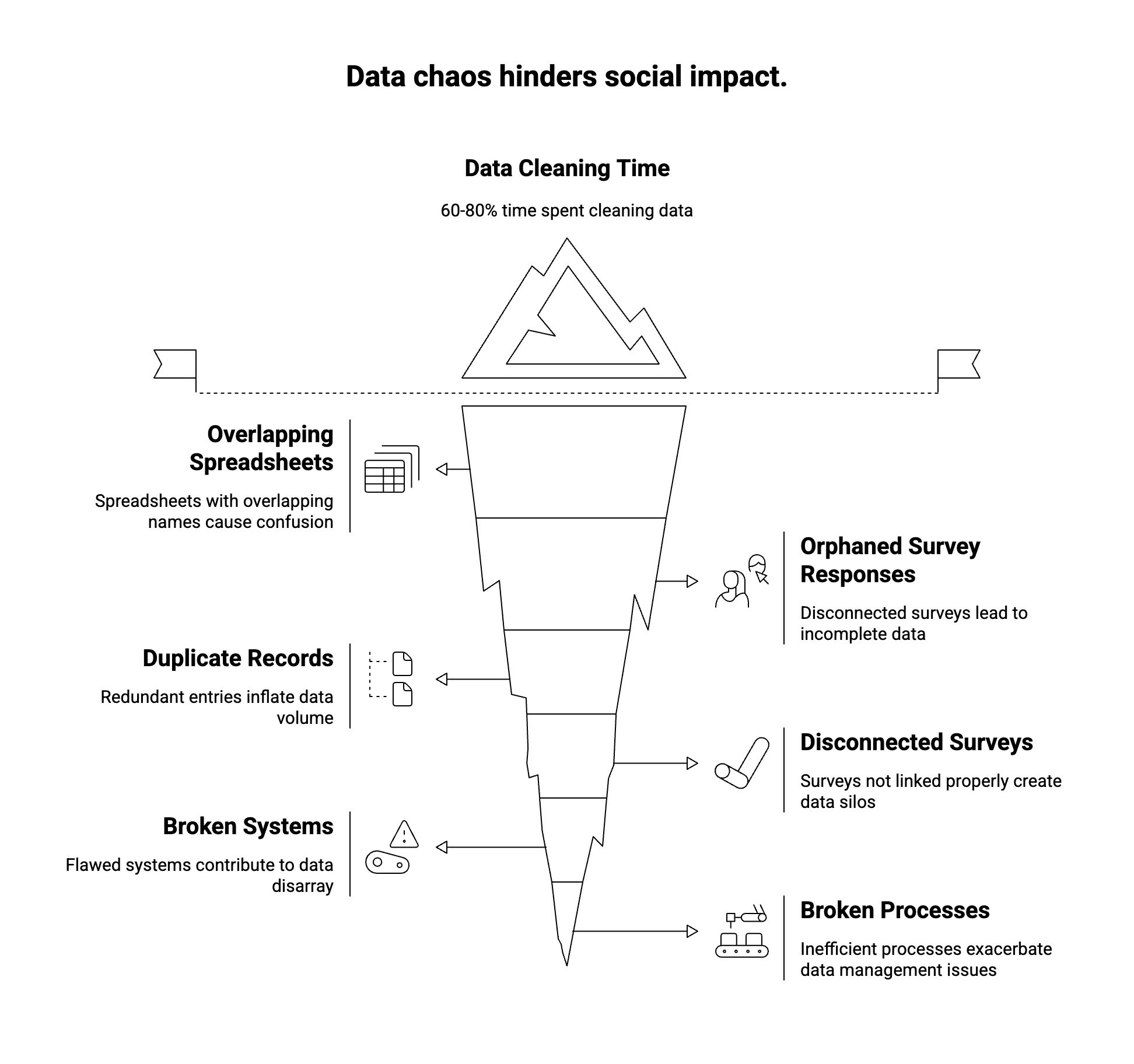
The promise of AI can turn that chaos into insight, but only if the data is prepared correctly. In plain terms, designing data for AI means setting up your data collection and management so that an AI can use it easily without endless fixing. As one guide puts it, you must “design your data for AI from day one” – collecting the right information, in the right way, with the right structure. Practically, this means giving every person a persistent unique ID (not just email or name), linking all their survey responses over time, and combining numeric ratings with rich stories. It also means building in checks – forms that prevent errors (no “age: banana” answers) and let people resume or correct answers. When done right, your AI tools can clean data automatically, spot trends, and even score open-ended feedback. But without this foundation, AI just “illuminates the mess” – it can’t fix broken data by magicsopact.com.
Recent surveys underline the gap. Only about 12% of organizations feel their data is truly AI-ready. Meanwhile, one report finds data teams spend up to 80% of their time cleaning and reconciling data for analysis. No wonder “data preparation” is often called the drudgery of analytics. In practice this means critical questions – like “is employment up for our youth?” or “are patients getting healthier?” – get stuck because the data pipeline is clogged. The good news is that by rethinking data design, we can reverse this trend.
Enter the next generation of data tools. Instead of bolting analytics onto old systems, AI-native platforms are built from the ground up for these problems. They promise to be lightweight and stakeholder-centric: easy to adopt (no month-long CRM installs), and focused on the people behind the data. One example is Sopact Sense, an “AI-native, collaborative platform built specifically for modern impact management”. Rather than just pushing out surveys, it ties every response to a person and a time. Importantly, it doesn’t treat qualitative feedback as an afterthought. Sopact’s system can ingest text comments, documents, photos, even audio, and “summarize, score, and analyze” them in minutes. In practice this means qualitative data analysis – tagging themes, measuring sentiment, extracting quotes – becomes automated. As Sopact explains, their AI uncovers “patterns, sentiment, and meaning in the qualitative data that tells the real story behind your numbers”. In other words, stakeholder voices aren’t lost; they are turned into actionable insight.
Crucially, AI-native design also means real-time dashboards and clean pipelines. One Sopact study promises real-time data access and predictive insights, not clunky exports. Your team sees live charts of progress, not stale spreadsheets. This eliminates the “export-clean-export” bottleneck of traditional tools. In short, platforms like this prepare data for AI by design – and then deliver on the AI promise, giving teams custom analytics and dashboards that actually drive decisions.
Consider a youth employment nonprofit. Every quarter they run skills workshops and job placements, and then survey participants about income, satisfaction, and experiences. Before adopting an AI-ready approach, they had a mess: one workshop used a Google form, another partner emailed PDFs, and a third team had a paper survey. Duplicates were rampant (some teens attended multiple sessions), and there was no way to track “what happened to Jamal last quarter” across these pieces. The data team spent weeks merging lists, guessing who was who, and still had holes.
Using AI-ready design changes the story. Sopact Sense would give each youth a unique survey link and ID at enrollment. All their answers – from pre-training to follow-ups – automatically tie together, no manual matching. If Maria reports new challenges in an open-ended field, the platform’s AI can tag themes (e.g. “transportation” or “childcare”) at scale. And staff can send a quick fix-it link if someone mistypes their email, without phone calls. The nonprofit now sees every youth’s journey: who found a job, whose work skills improved, and which barriers keep popping up. This stakeholder data tracking means analysis (even AI-driven predictions of who needs extra support) can happen weekly instead of yearly.
A health NGO illustrates another win. They wanted to evaluate patient well-being over time, but initially they were stuck. Using simple Google Forms with no common ID, each survey round was disconnected. As a result, “they couldn’t compare responses over time. No AI could help”. The staff felt helpless: every time doctors asked “is our intervention improving health?”, they had no good answer.
After switching to a data design built for AI, everything changed. Each patient got a persistent link and ID across months of surveys. Open-ended notes from nurses (like “patient worried about rent”) were automatically tagged by AI with relevant issues. Follow-up forms checked the same people again, so the team could see if moods or symptoms shifted. A dashboard tracked patient progress by clinic and by individual. Suddenly the NGO had real-time insight: they could see which treatments were helping, and the funders could even visualize impact trends. All this was possible because the data pipeline was clean at the start, not after a cleanup marathon.
Foundations and grantmakers also struggle with scattershot data. Imagine a funder asking 30 grantees for quarterly updates. Without a unified system, one grantee might email a Word doc, another a survey, and a third just forget to mention a program outcome. Worse, anonymous survey links might be used so no one can tie feedback back to the right grantee or project. This creates “blind spots” in impact evaluation: comments like “I’m concerned about this metric” float without a name, and errors (typos, missing values) multiply.
Sopact Sense addresses this with built-in relationships and IDs. Each grantee’s reports come through unique links, automatically labeled by project and quarter. No two entries get conflated, and nothing is anonymous by accident: every feedback item has its source. If a grantee sees “outlier” data, staff can re-open that specific form for editing. The result is a clean, connected dataset. Evaluators can then run AI tools or analytics and trust the outputs. For example, a word cloud or sentiment gauge can be generated from all grantee comments, confident that each phrase is tied to the right context.
These examples highlight common pitfalls in social impact data. Duplicate records often arise when the same person fills out multiple forms without a master ID. Disconnected surveys happen when pre/post or partner-collected data aren’t linked. Anonymous feedback without follow-up ability means valuable context is lost. Traditional tools almost invite these problems. In fact, Sopact notes that in old systems up to 80% of effort went into cleaning and reconciling data. In contrast, Sopact Sense “fixes this at the source”: it eliminates duplicate entries and broken links by design. For example, their documentation assures that with unique survey links “it is impossible to have duplicate records, our system takes care of that automatically”. Every form response is immediately connected to the right person and project. Built-in data validation catches typos (no one can enter “banana” for age), and resume links mean incomplete surveys get finished later.
Another pitfall is manual open-ended analysis. Many teams simply ignore free-text feedback or spend months coding it by hand. In an AI-ready platform, this work is automated. Sopact’s “Intelligent Cell” feature, for instance, instantly highlights what stakeholders are saying. It “sees what they’re saying, quantifies key patterns, and generates actionable scores”. You no longer postpone text analysis; themes and sentiment emerge in real time, feeding impact evaluation AI models with clean inputs.
Designing AI-ready data isn’t just a tech buzzword – it’s a mindset shift for social impact work. By focusing on clean data for AI from the start, organizations turn the chore of evaluation into a continuous learning engine. Every unique ID, every linked form, and every auto-tagged comment builds a foundation where AI and dashboards can shine. As Sopact puts it, the future of impact lies “before the algorithms – with how you ask, listen, and track”. In this future, data teams at NGOs, health programs, and foundations can spend far less time fixing past mistakes and far more time unlocking real stories of change. AI-ready data design thus transforms frustrated dashboards into powerful insight, amplifying social impact one dataset at a time.
Sources: Industry studies and Sopact documentation on data cleaning, AI readiness, and social impact platforms.





