Time to Rethink Data Cleaning Tools for Today’s Needs
Imagine data cleaning platforms that evolve with your needs, keep records pristine from the first entry, and feed AI-ready datasets in seconds—not months.
Build and deliver a rigorous data cleaning strategy in weeks, not years. Learn step-by-step guidelines, tools, and real-world examples—plus how Sopact Sense makes the whole process AI-ready.

Data teams spend the bulk of their day fixing silos, typos, and duplicates instead of generating insights.
Data teams spend the bulk of their day fixing silos, typos, and duplicates instead of generating insights.
Hard to coordinate design, data entry, and stakeholder input across departments, leading to inefficiencies and silos.
Open-ended feedback, documents, images, and video sit unused—impossible to analyze at scale.
In the age of AI and automated insights, data cleaning isn't just a backend chore—it’s the foundation of decision-making.
When organizations rely on messy, duplicate-filled, or outdated records, they risk everything from missed funding to flawed strategies. But today, there’s a smarter way.
This article shows how AI-powered data cleaning tools go beyond spreadsheets and scripts. They enable real-time validation, correction, and collaboration—so you're always working with trusted data.
📊 Stat to Know: IBM estimates poor data quality costs U.S. businesses over $3 trillion per year in lost productivity and bad decisions.
“Clean data isn’t a luxury—it’s a requirement. We can’t analyze or act without it.” — Sopact Team
Data cleaning refers to the process of detecting and correcting (or removing) inaccurate, incomplete, or irrelevant data from a dataset. It’s the crucial first step before analysis, reporting, or decision-making.
Manual data cleaning is time-consuming and error-prone. Most teams spend up to 80% of their time wrangling data—fixing duplicates, missing values, or inconsistent formats.
AI-native platforms like Sopact Sense transform this workflow:
Whether you’re dealing with 1,000 survey responses or 10,000 participant records, you get clean, ready-to-analyze data in hours—not weeks.
Data cleaning with Sopact Sense isn’t just about fixing errors—it’s about trusting your data from the start and collaborating with stakeholders to improve it continuously.
Generative-AI projects, real-time dashboards, and automated customer journeys each depend on pristine inputs. When names are misspelled, IDs collide, or timestamps drift, algorithms over-fit, KPIs mislead, and decisions stall. The gap between aspiration and reality is stark: while executives pursue “AI at scale,” data teams remain janitors, shepherding CSVs through brittle spreadsheets. Gartner’s latest Magic Quadrant for Augmented Data Quality even warns that sub-standard datasets can “break AI initiatives before they begin”qlik.com.
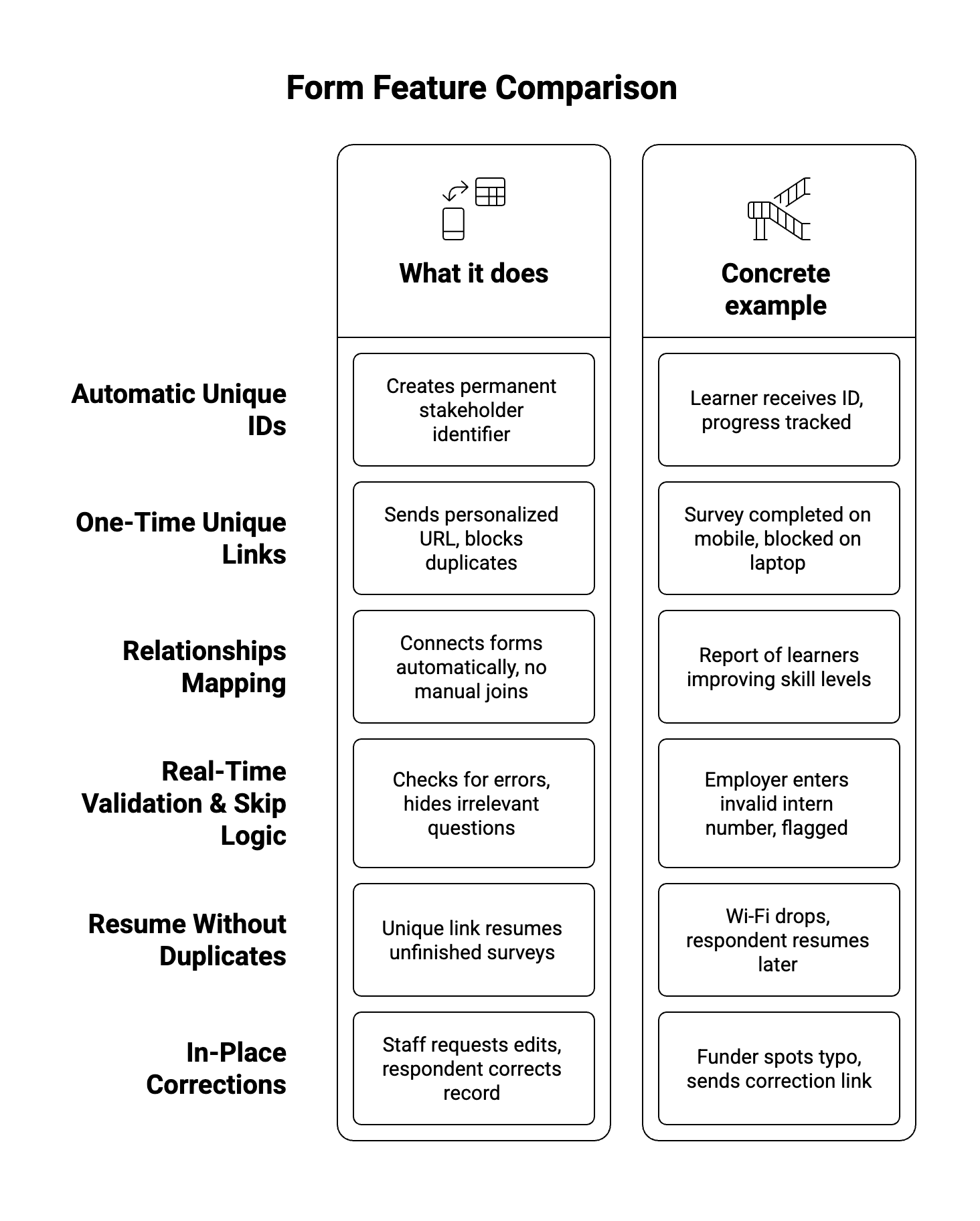
Traditional data cleaning followed a batch mentality: export, patch, reload, repeat. Modern practice flips the sequence—embedding validation, unique IDs, and semantic checks at the moment of capture, then piping clean, transformed data straight into analysis. Sopact Sense exemplifies this shift: its Contacts, Relationships, and Intelligent Cell modules guarantee that every respondent carries a persistent ID, duplicate surveys are impossible, and open-ended feedback is analysed the instant it arrivesSopact Sense Concept.
Each category tackles overlapping but distinct pain points—from schema drift to phonetic matching—and many organisations deploy two or more, orchestrated through data pipelines.
The boundaries blur in practice, but clarity on terminology helps when comparing vendor claims. For example, Integrate.io positions itself as an ETL-plus-cleaning tool, whereas Sopact Sense markets proactive ID management and qualitative-data parsing—functions that live at the collection edge, not in the warehouse.
A training non-profit collected intake and exit surveys in SurveyMonkey and stored attendance in Excel. Names diverged (“Ana García” vs “Anna Garcia”), e-mails changed, and no common key existed. A switch to Sopact Sense linked each participant to a durable Contact record, enforced single-response links, and auto-merged historic duplicates, slashing weekly reconciliation from eight hours to thirty minutesLanding page - Sopact S….
A retailer used RingLead to merge CRM and e-mail-service lists, then Informatica Cloud to de-accent international characters and standardise country codes. Cart-abandonment models subsequently lifted conversion by 12 %.
A bank layered Melissa address verification and Qlik’s augmented data quality alerts onto its onboarding portal; false-positive fraud flags dropped 18 % within one quarter.
These vignettes illustrate that success hinges less on any single product than on stitching tools around a clear, organisation-wide data quality framework.
Deduplication: phonetic matching, fuzzy joins, and unique-link distribution stop multiple records at the door.
Validation: regex, range checks, and referential constraints flag out-of-bounds values in real time.
Standardisation: reference data (e.g., ISO country codes), case normalisation, and locale-aware date parsing create uniformity.
Missing-Value Handling: context-aware defaults, statistical imputation, or targeted call-backs via unique record links.
Outlier Detection: AI-based anomaly scanning, like Mammoth Analytics’ embedded models.
Documentation and Lineage: automatic audit trails inside platforms such as Informatica Cloud or Sopact’s Intelligent Cell.
Begin by clarifying the business question that makes bad data costly—revenue attribution, donor retention, compliance. Next, profile your sources: where do records originate, what errors recur, which fields are mission-critical? Assign owners at both system and field level to enforce standards. Select cleaning tools that match each failure mode: deduplication, validation, enrichment. Pilot on a representative slice, measuring error-rate reduction and time saved. Document rules, create automated tests, and schedule monitoring alerts so yesterday’s clean table doesn’t become next quarter’s headache. Finally, institutionalise feedback loops: when frontline teams spot anomalies, route them back through unique links for correction rather than patching downstream reports.
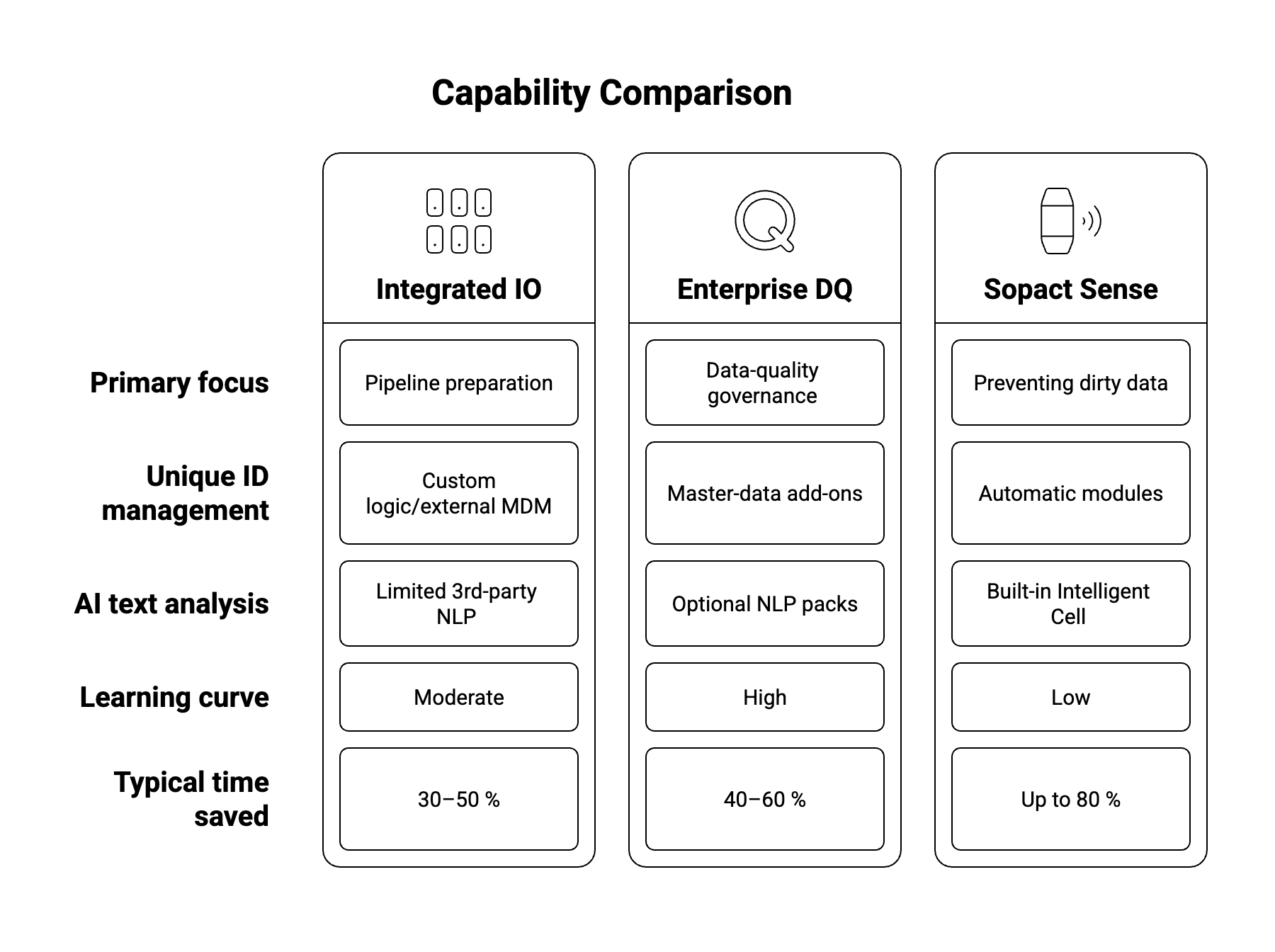
Sopact Sense is not a full Master-Data-Management suite. It won’t govern every ERP field or reconcile clickstream logs. Its strength lies where most legacy tools are weakest: collecting stakeholder feedback that is inherently unstructured, longitudinal, and relationship-heavy. By fusing ID control, skip-logic, advanced validation, and AI-driven qualitative analytics at the point of entry, it removes the most labour-intensive layers of cleaning before they ever appear in a warehouse.
In pilots with funds and accelerators, clients trimmed reporting cycles from six weeks to five days while increasing confidence in trend analysis across cohorts. For deeper transactional cleansing—addresses, payments, telemetry—Sense integrates via CSV or API with mainstream platforms, proving that proactive and reactive cleaning can coexist.
Data cleaning tools once lived in the shadows, invoked only after dashboards broke. Today they occupy the strategic core of every AI roadmap. Whether you choose an all-in-one cloud platform, stitch best-of-breed validators, or adopt an AI-native survey engine like Sopact Sense, the mandate is clear: quality in, insight out. Start with the checklist above, map each pain point to a technique, automate wherever feasible, and measure progress ruthlessly. Because in 2025, the winner isn’t the organization with the most data—it’s the one with data it can trust.




